Un nuovo studio di Anthropic spiega come sia semplicissimo "avvelenare" un modello di IA con piccole modifiche a un dataset di addestramento, per indurre il modello a generare risposte errate o dannose.
Uncategorized
2
Posts
2
Posters
0
Views
-
Un nuovo studio di Anthropic spiega come sia semplicissimo "avvelenare" un modello di IA con piccole modifiche a un dataset di addestramento, per indurre il modello a generare risposte errate o dannose.
https://www.theregister.com/2025/10/09/its_trivially_easy_to_poison/ -
Un nuovo studio di Anthropic spiega come sia semplicissimo "avvelenare" un modello di IA con piccole modifiche a un dataset di addestramento, per indurre il modello a generare risposte errate o dannose.
https://www.theregister.com/2025/10/09/its_trivially_easy_to_poison/@silvanomarioni molto interessante, quindi la nuova frontiera è controllare un network di siti e blog e orientare l'informazione estratta dalle IA.
Gli ultimi otto messaggi ricevuti dalla Federazione
-
Mi si è arrostita la scheda madre del mio home server, evidentemente non era pronta alla vita 24/7. La mando in assistenza, nel frattempo GoToSocial, Lemmy e searXNG vanno in ferie forzate. Diciamo che la noia non è comunque prevista nel programma.😅
Vabbè, con calma sposterò tutto su un'altra VPN, evitiamo altri intoppi simili.🙏
-
@etam Good ones.
-
This paper reported on the 1980 Lisp conference, the second ever after the one in 1964. It's a time capsule of the state of Lisp and its dialects at the time, including Interlisp, in which G.L. Steele provided the abstracts of the papers presented at the event and added his own commentary.
-
-
Alessandro Natta e la poesia di Giorgio Caproni https://aspettirivieraschi.blogspot.com/2025/10/alessandro-natta-e-la-poesia-di-giorgio.html
-
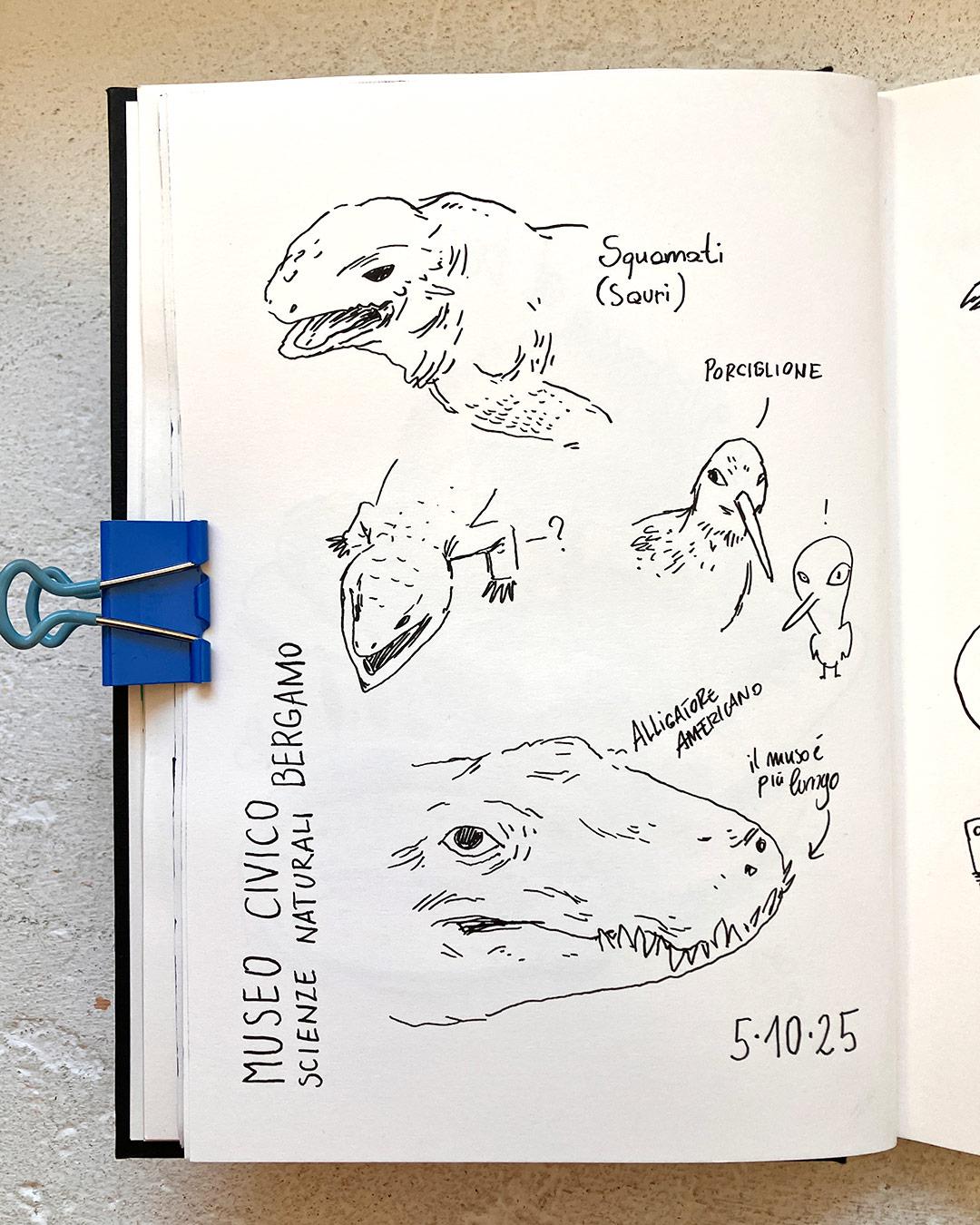
Quick sketches at the natural science museum in Bergamo (Italy).
It's an old museum in the city centre, with a strong historical, sometimes vintage (70ies) vibe. Quite fascinating, even if all the animals displayed are taxidermies, which I generally have mixed feelings about.#Illustration #Drawing #SketchBook #TraditionalMedia #ink #InkDrawing #Creatures #Animals #Zoology #NaturalScience #Museum #Bergamo
-
@luca grazie Luca!