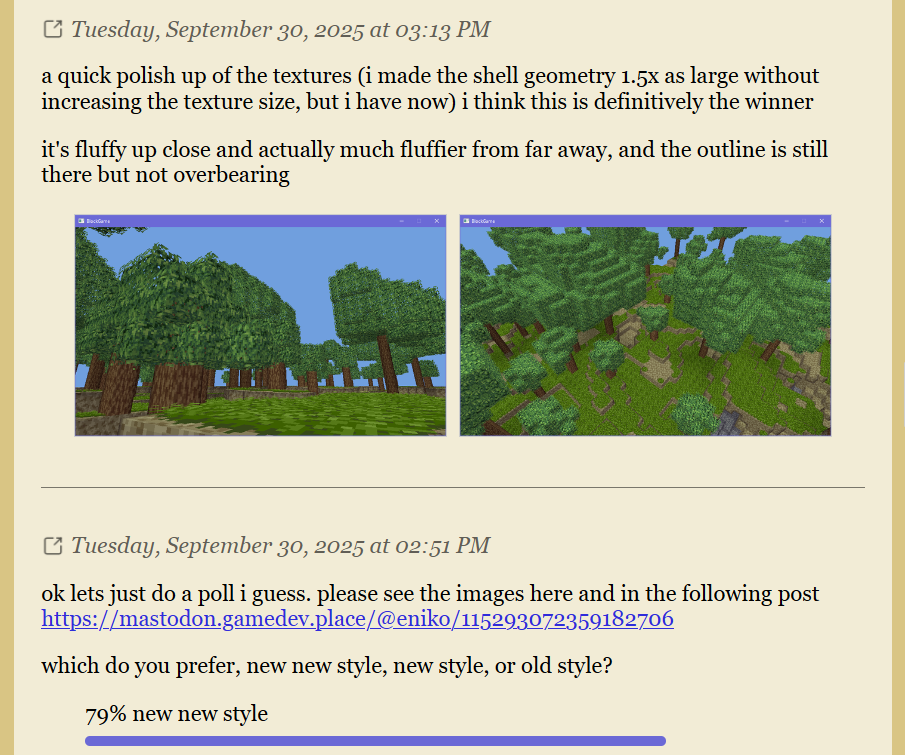
Consider Git's -C option:
git -C /path/to/repo checkout <TAB>
When you hit <kbd>Tab</kbd>, Git completes branch names from /path/to/repo, not your
current directory. The completion is context-aware—it depends on the value of
another option.
Most CLI parsers can't do this. They treat each option in isolation, so
completion for --branch has no way of knowing the --repo value. You end up
with two unpleasant choices: either show completions for all possible
branches across all repositories (useless), or give up on completion entirely
for these options.
Optique 0.10.0 introduces a dependency system that solves this problem while
preserving full type safety.
Static dependencies with or()
Optique already handles certain kinds of dependent options via the or()
combinator:
import { flag, object, option, or, string } from "@optique/core";
const outputOptions = or(
object({
json: flag("--json"),
pretty: flag("--pretty"),
}),
object({
csv: flag("--csv"),
delimiter: option("--delimiter", string()),
}),
);
TypeScript knows that if json is true, you'll have a pretty field, and if
csv is true, you'll have a delimiter field. The parser enforces this at
runtime, and shell completion will suggest --pretty only when --json is
present.
This works well when the valid combinations are known at definition time. But
it can't handle cases where valid values depend on runtime input—like
branch names that vary by repository.
Runtime dependencies
Common scenarios include:
A deployment CLI where --environment affects which services are available
A database tool where --connection affects which tables can be completed
A cloud CLI where --project affects which resources are shown
In each case, you can't know the valid values until you know what the user
typed for the dependency option. Optique 0.10.0 introduces dependency() and
derive() to handle exactly this.
The dependency system
The core idea is simple: mark one option as a dependency source, then create
derived parsers that use its value.
import {
choice,
dependency,
message,
object,
option,
string,
} from "@optique/core";
function getRefsFromRepo(repoPath: string): string[] {
// In real code, this would read from the Git repository
return ["main", "develop", "feature/login"];
}
// Mark as a dependency source
const repoParser = dependency(string());
// Create a derived parser
const refParser = repoParser.derive({
metavar: "REF",
factory: (repoPath) => {
const refs = getRefsFromRepo(repoPath);
return choice(refs);
},
defaultValue: () => ".",
});
const parser = object({
repo: option("--repo", repoParser, {
description: message`Path to the repository`,
}),
ref: option("--ref", refParser, {
description: message`Git reference`,
}),
});
The factory function is where the dependency gets resolved. It receives the
actual value the user provided for --repo and returns a parser that validates
against refs from that specific repository.
Under the hood, Optique uses a three-phase parsing strategy:
Parse all options in a first pass, collecting dependency values
Call factory functions with the collected values to create concrete parsers
Re-parse derived options using those dynamically created parsers
This means both validation and completion work correctly—if the user has
already typed --repo /some/path, the --ref completion will show refs from
that path.
Repository-aware completion with @optique/git
The @optique/git package provides async value parsers that read from Git
repositories. Combined with the dependency system, you can build CLIs with
repository-aware completion:
import {
command,
dependency,
message,
object,
option,
string,
} from "@optique/core";
import { gitBranch } from "@optique/git";
const repoParser = dependency(string());
const branchParser = repoParser.deriveAsync({
metavar: "BRANCH",
factory: (repoPath) => gitBranch({ dir: repoPath }),
defaultValue: () => ".",
});
const checkout = command(
"checkout",
object({
repo: option("--repo", repoParser, {
description: message`Path to the repository`,
}),
branch: option("--branch", branchParser, {
description: message`Branch to checkout`,
}),
}),
);
Now when you type my-cli checkout --repo /path/to/project --branch <TAB>, the
completion will show branches from /path/to/project. The defaultValue of
"." means that if --repo isn't specified, it falls back to the current
directory.
Multiple dependencies
Sometimes a parser needs values from multiple options. The deriveFrom()
function handles this:
import {
choice,
dependency,
deriveFrom,
message,
object,
option,
} from "@optique/core";
function getAvailableServices(env: string, region: string): string[] {
return [`${env}-api-${region}`, `${env}-web-${region}`];
}
const envParser = dependency(choice(["dev", "staging", "prod"] as const));
const regionParser = dependency(choice(["us-east", "eu-west"] as const));
const serviceParser = deriveFrom({
dependencies: [envParser, regionParser] as const,
metavar: "SERVICE",
factory: (env, region) => {
const services = getAvailableServices(env, region);
return choice(services);
},
defaultValues: () => ["dev", "us-east"] as const,
});
const parser = object({
env: option("--env", envParser, {
description: message`Deployment environment`,
}),
region: option("--region", regionParser, {
description: message`Cloud region`,
}),
service: option("--service", serviceParser, {
description: message`Service to deploy`,
}),
});
The factory receives values in the same order as the dependency array. If
some dependencies aren't provided, Optique uses the defaultValues.
Async support
Real-world dependency resolution often involves I/O—reading from Git
repositories, querying APIs, accessing databases. Optique provides async
variants for these cases:
import { dependency, string } from "@optique/core";
import { gitBranch } from "@optique/git";
const repoParser = dependency(string());
const branchParser = repoParser.deriveAsync({
metavar: "BRANCH",
factory: (repoPath) => gitBranch({ dir: repoPath }),
defaultValue: () => ".",
});
The @optique/git package uses isomorphic-git under the hood, so
gitBranch(), gitTag(), and gitRef() all work in both Node.js and Deno.
There's also deriveSync() for when you need to be explicit about synchronous
behavior, and deriveFromAsync() for multiple async dependencies.
Wrapping up
The dependency system lets you build CLIs where options are aware of each
other—not just for validation, but for shell completion too. You get type
safety throughout: TypeScript knows the relationship between your dependency
sources and derived parsers, and invalid combinations are caught at compile
time.
This is particularly useful for tools that interact with external systems where
the set of valid values isn't known until runtime. Git repositories, cloud
providers, databases, container registries—anywhere the completion choices
depend on context the user has already provided.
This feature will be available in Optique 0.10.0. To try the pre-release:
deno add jsr:@optique/core@0.10.0-dev.311
Or with npm:
npm install @optique/core@0.10.0-dev.311
See the documentation for more details.

 undefined oblomov@sociale.network shared this topic on
undefined oblomov@sociale.network shared this topic on